
Tesla架构
GPU架构——Tesla架构
笔者学习自:GPU 架构探秘之旅中的文章,因此文章内容可能与其相似。
本文仅用于记录笔者日常学习、总结学习笔记,不作商业用途
这系列文章中,我认为需要学习的是 GPU 结构和并行思想,具体涉及到计算机图形学的部分可以略看。
初始 GPU 架构
1999 年,图形加速器才有和 CPU 平分秋色的 GPU 的名字。当时是 GeForce 256 享此殊荣。可以把坐标变换、灯光照明、三角形设置裁剪和每秒处理一千万个多边形的渲染引擎集成到一个芯片上,在现在看来由 GPU 负责是天经地义的,但在当时,却是相当大的突破。
对大量数据执行相同操作(SIMD),是并行计算的最爱,也是GPU得以分家立业并不断从CPU挖墙脚的万恶之源。而GeForce 256只是这万里长征梦最开始的地方,但其大量数据具体执行什么操作是内置的(固定管线),这不还是特定算法的加速器而已么,怎配得上处理器三个字?
所以两年后,GeForce 3拥有了顶点着色器和可配置的片元管线,进入了DirectX8的时代;而第二年也就是2002年,ATI(后被AMD收购,此时应该是ATI YES?)发布了Radeon9700,其支持24位可编程的片元着色器,直接拥抱DirectX9;英伟达在2003年也发布了支持32位可编程片元的GeForce FX,虽然初始型号有点拉跨2。
在这个“上古混沌”时期,GPU走在一条不断提高可编程性的康庄大道上,而终于在2006年随着基于Tesla架构构建的第八代GeForce推出,迎来了一股小高潮。我们也迎来了本文的主角——Tesla架构。
破开麻雀的身体
与现在动辄上万个核的3090相比,Tesla架构寒酸得让人心疼。但麻雀虽小五脏俱全,非常适合刚接触GPU架构的我们学习(直接看最新显卡的架构图,在看清楚前眼睛已经瞎了)。
而随着我们在之后的文章中一步步沿着显卡的演化路径前进到当下,我们会惊奇地发现,Tesla架构所奠定的基础设施框架,以及其所蕴含的设计思想历久弥新,从未过时。
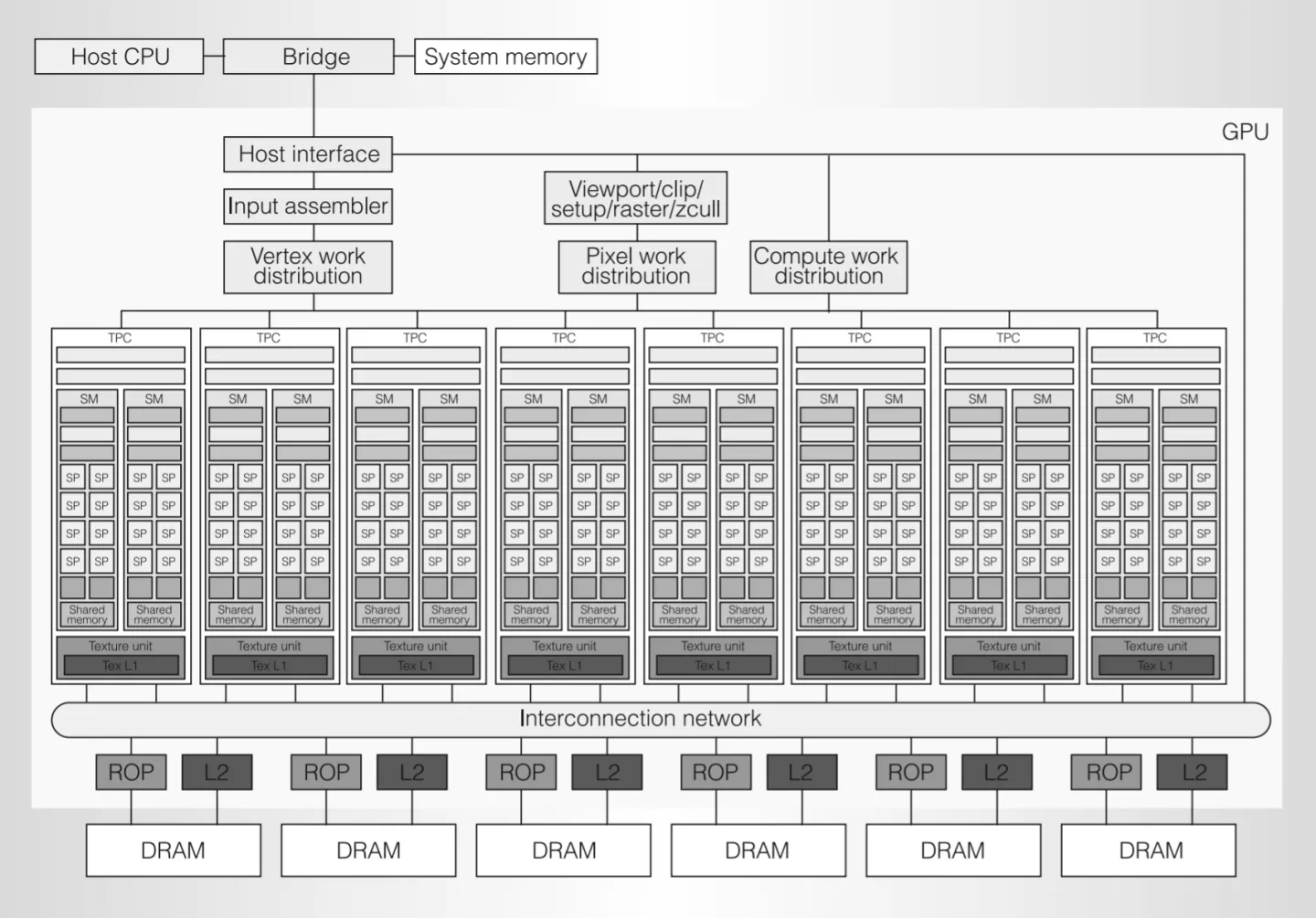
简单划分一下:
- 最上面是甲方 CPU;整个 GPU 可以看成一个外包公司,负责各种又脏又累的活
- 外包公司内,最上层的是各种大小包工头;中间是负责干活的工人;最下方是对方原料的码头和仓库
- 可以发现一个特点:除了负责指挥的包工头,下面干活的工人和数据码头和仓库似乎有好几个,并且长得一模一样,这是GPU 并行性在具体硬件结构上的体现。
劳动人民
Host Interface:外包公司大包工头,负责收发来自 CPU 的各种订单,并处理 GPU 在各种订单间的上下文切换;负责获取来自内存等待加工的原材料(顶点数据、纹理数据、buffer等)并放到显存中。
Input Assembler:将顶点索引和图元类型搭配,并搭配它们的顶点属性,才能传给 Vetex Work Distribution
Vertex、Pixel、Compute Work Distribution:三个小包工头,分别分发顶点、片元和计算着色器的任务,给底下的一堆流水线工人去做。
TPC(Texture Processing Clusters):内部有一个纹理单元和两个负责计算的 SM(Streaming Multiprocessor)。上面三个小包工头的任务由它们完成,是个啥都能做的“全栈工程师”。
Viewport/clip/setup/raster/z-cull block:(笔者没有搞明白这是干啥的,将原文摘录如下)顶点着色器处理完,只是输出一堆裁剪坐标(还未透视除法)和一堆与其一起等待光栅化插值的属性,这个模块就是负责这些,流水线中到目前为止都未开放编程的固定功能部分。
ROP(Raster Operations Processor):码头工人,负责对片元着色器处理后的像素进行测试和装箱:同一个像素位置的深度/模板测试和写入、颜色混合、抗锯齿有他完成。
L2 Cache、Memory Controller 和 DRAM:每个 DRAM 搭配一个 Memory Controller、L2 Cache 和一个 ROP,共有 6 组这样的搭配,每个搭配对应显存六分之一的物理地址。
血汗工厂
上一个部分中我们简单浏览了一下 Tesla 架构的整体框架和主要部件,真正干活的是 TPC(Texture Processing Clusters)及其内部的 SM(Streaming Multiprocessor)。促使它们 007 工作的机制,是 GPU 拥有巨大并行能力的核心秘密。
走进黑心企业
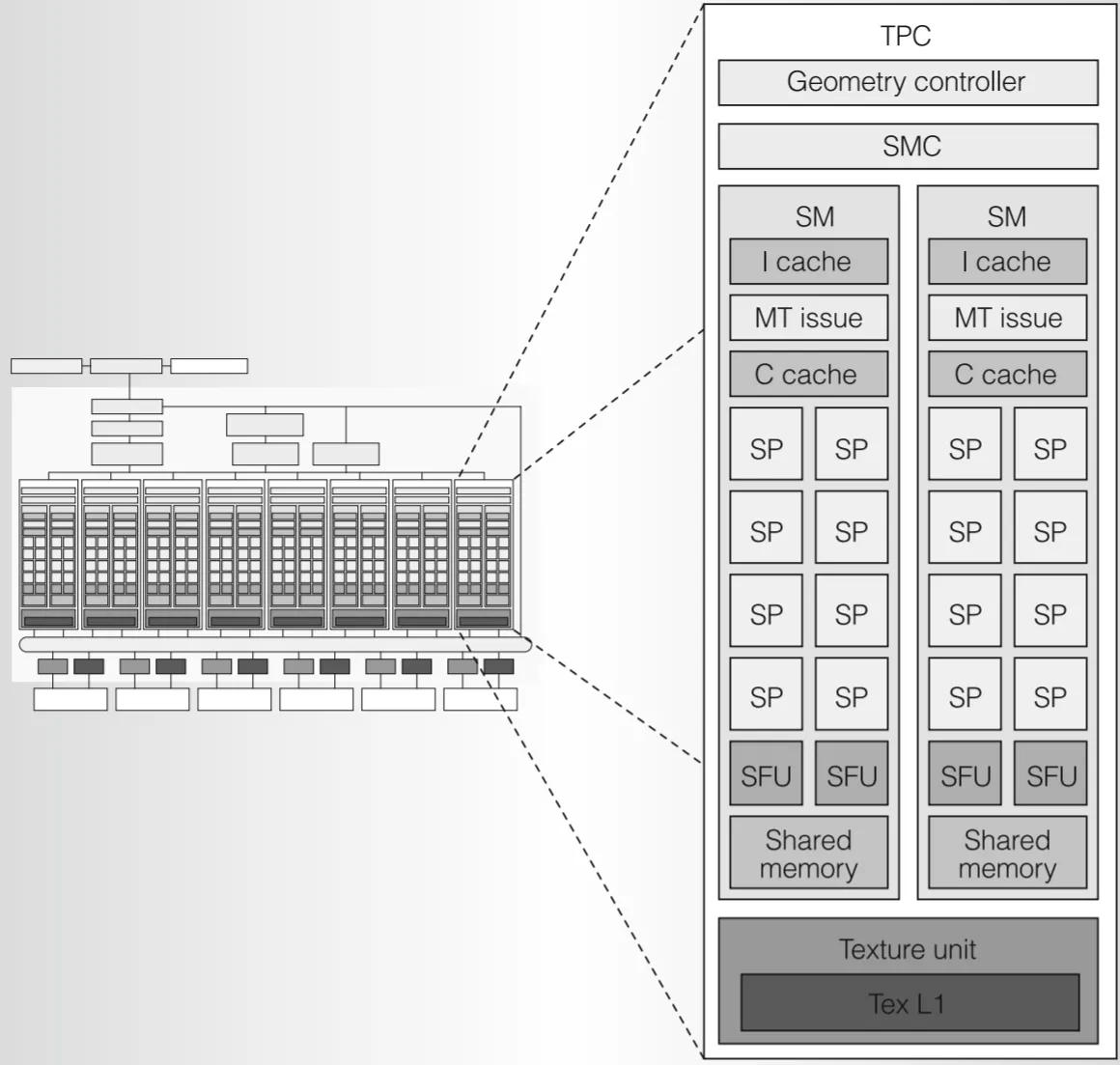
我们可以将 TPC 内部看成一个个子公司,黑心企业一共由 8 个。
Geometry Controller(几何控制器):光栅化前几何阶段,负责顶点属性在芯片内输出相关事宜(我觉得可以不用管具体在图形学中的工作内容)。
SMC(SM Controller):Tesla 是统一的图形和并行计算架构,顶点、几何、片元着色器,甚至与图形无关的并行计算任务(CUDA)都由同样的硬件 SM 来运算。SMC 负责将来自总部的各种任务,拆分打包成 Warp 交给 SM 处理。同时,SMC 还负责协调 SM 与公用部门 Texture Unit 之间的工作,实现对外纹理资源的获取;现存中其他非纹理资源的读写甚至原子操作通过 ROP 与外界打交道。总之,SMC 由负责对接外界资源,又负责内部任务分配,实现复杂但至关重要的负载平衡,是名副其实的子公司高管。
Texture Unit:包括 4 个纹理地址生成器和 8 个滤波单元。纹理单元的指令源是纹理坐标,输出是经过插值的纹理值,都是向量。
SM(Streaming Multiprocessor):负责最底层运算的部门
- I Cache(指令 Cache):一个 SM 要做的来自 SMC 的工作并非立刻完成,大量指令被缓存到这里分批执行
- C Cache(常量 Cache)和 Shared Memory(共享内存):讲通用计算和各种内存类型时再展开
- MT(Multi-threaded) Issue:SM部门主管,负责将 Warp 任务拆碎成一条条指令分给社畜们执行。对 Warp 的调度是 GPU 并行能力的关键。
- SP(Streaming Processor):干活的主力军,执行最基本的浮点型标量运算,包括 add、multiply、multiply-add,以及各种整数运算。
- SFU(Special Function Unit):负责更为复杂的运算,比如超越函数(指数、对数、三角函数等)、属性插值、透视矫正
一条绳上的蚂蚱
干活流程:高级语言——编译成中间指令——被优化器转化为二进制 GPU 指令。
- 高级语言包括:着色器代码、CUDA Kernel 程序等
- 中间指令如果是 SIMD,则会被转化为多条 Tesla SM 标量指令
ISA(Instruction Set Architecture):那么都会生成哪些指令呢?主要有三类:
- 运算:浮点整数等加法乘法、最小最大、比较、类型转换等基础运算以及超越函数等复杂运算。
- 流控制:分支、调用、返回、中断、同步
- 内存访问:包括对各类内存的读写、原子操作
这些指令 CPU 也可以做,但是为什么交给 GPU 呢?因为这些指令不仅需要做一遍。比如一个顶点着色器,没有一个顶点数据,就要开一个线程把这个指令做一遍。
SMC 拿到一个着色器所有指令之后,会把这些指令以 32 个线程为单位分发给 SM,负责执行完这个着色器所有指令的 32 个线程,成为一个 Warp。
指令存放于指令 Cache 中,MT Issue 每次拿出一个指令分发给手下 SP 或者 SFU 执行。
一个 SM 中 SP 只有 8 个,但是需要运行 32 个线程(Warp),所以让每个 SP 连续干 4 次。
一个 MT Issue 发号施令一次,手下的 SP 和 SFU 就将一条指令执行 32 次,这就是 SIMT(Single-instruction, multiple-thread),GPU 基于 SIMT 设计的。
分支情况
每个线程其实不一定执行相同的指令,程序并非简简单单的一条条向下走,而是还有分支、循环等改变指令流的情况,由于每个线程输入的数据不同,很可能进入不同的分支。
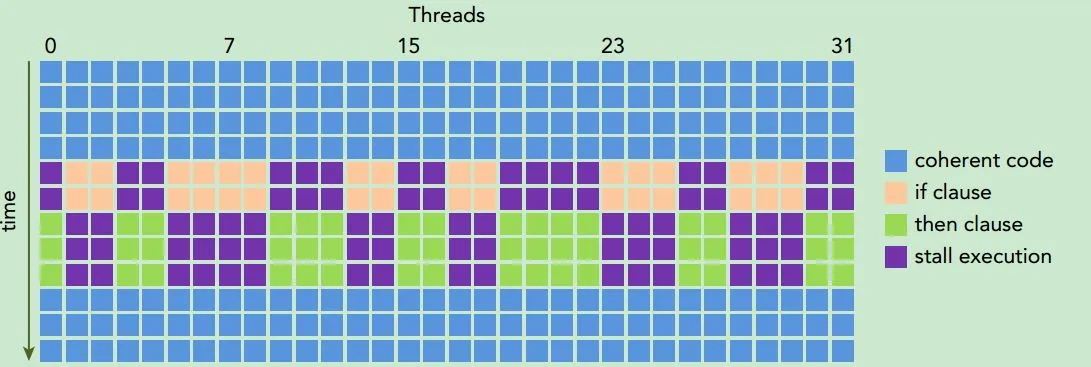
解决方法:
- 编译器可以进行特殊情况下的分支预测
- 无法预测的情况下,需要付出指令代价进行 Warp Voting,投票出 Warp 中所有线程只走一个分支还是串行走多个分支(即使只有一个线程进入了某个分支,其他线程也需要等待它执行完毕,这就是锁步运行)
活儿可以等,打工人不能等
当前硬件的计算速度比访存速度快几个数量级,瓶颈往往在访存上。当 SP 遇到内存访问指令,会由 SMC 向外请求数据(要么通过纹理单元要么通过 ROP)
社畜SP:“没办法呀,我也不是真的想摸鱼,但是没数据我干不了接下来的活呀 :)”
主管MT Issue:“是的,这个Warp只能等了,毕竟不同指令间有数据依赖,着色器里的代码总不能跳着执行。”
社畜SP:“是呀是呀,这活总得按部就班,才不会忙中出错嘛”
子公司高管SMC:“总部摊派给我们的活多着呢,我特意拆分成了好多个Warp让你们执行,就是想避免你们带薪拉屎。一个Warp要拿数据,我去帮你们联系就行,你们赶紧先去做其他Warp!”
于是,整个部门007的日常开始了。
这就是延迟隐藏的真相。公司特地搞了一个指令 Cache,就是让 SM 能够存储下足够多的 Warp(Tesla 架构最多 24 个,这些 Warp 可以是不同类型的,比如顶点着色器、片元着色器甚至是 CUDA 程序),以便在内存阻塞时快速切换到其他可以执行的 Warp 上,等拿到数据之后再切换回原来的 Warp 就行了。毕竟,读写数据不需要 SP 费心。有足够多的 Warp 让 SP 们 007。
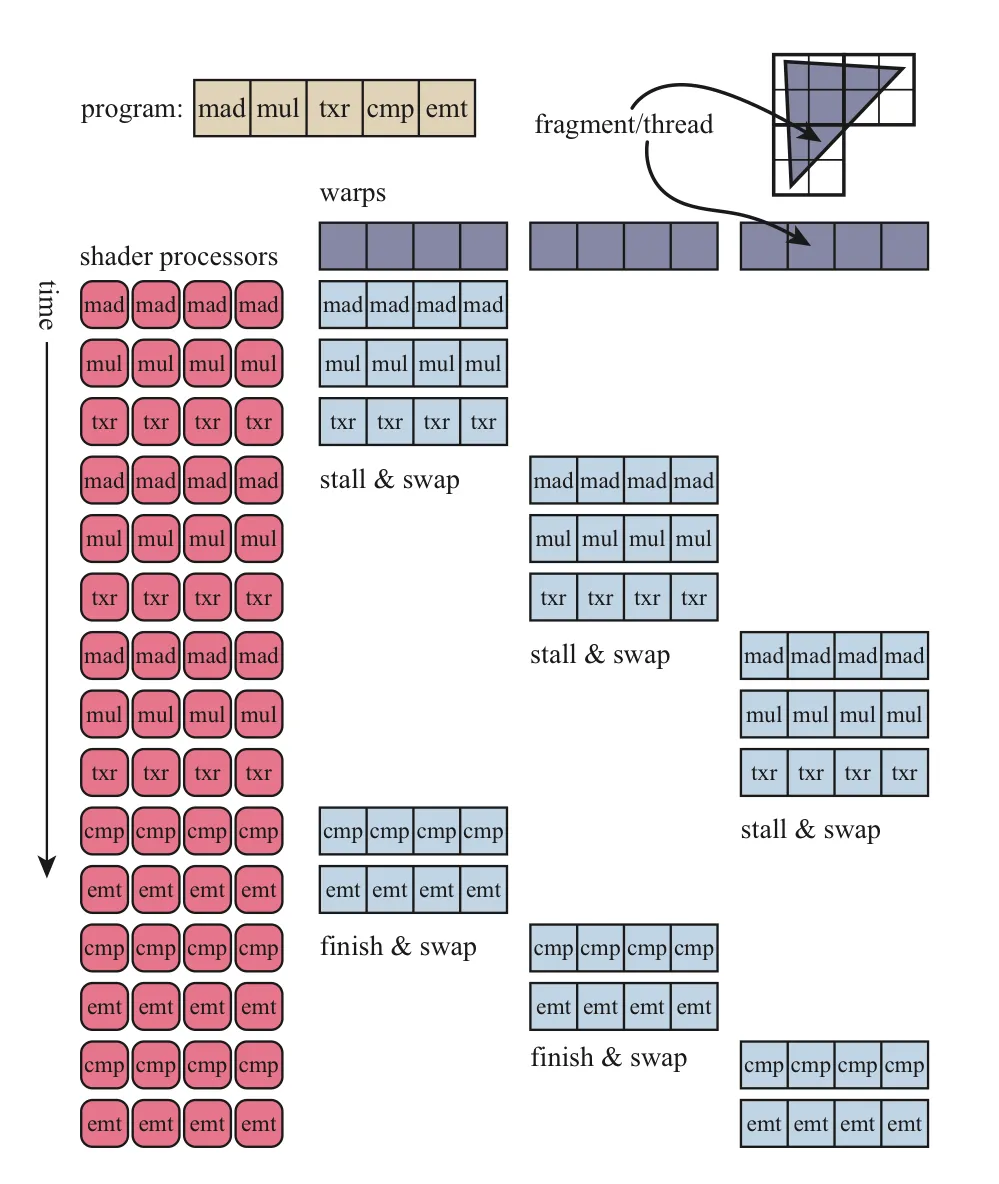
并行的真相:不是简单的计算单元并行,而是所有元器件尽可能都不要停下来。当然 MT Issue 也停不下来,大家都是打工人,谁也不必谁高贵。
MT Issue 从原来的分发一个 Warp 的一条指令变成了从多个 Warp 中挑选一个 Warp 执行其之前执行到的接下来的指令。将会根据 Warp 类型、指令类型和公平性原则来量化选择 Warp。每两个周期,MT Issue 从中挑选一个得分最高的 Warp 分配给对应的元器件执行。
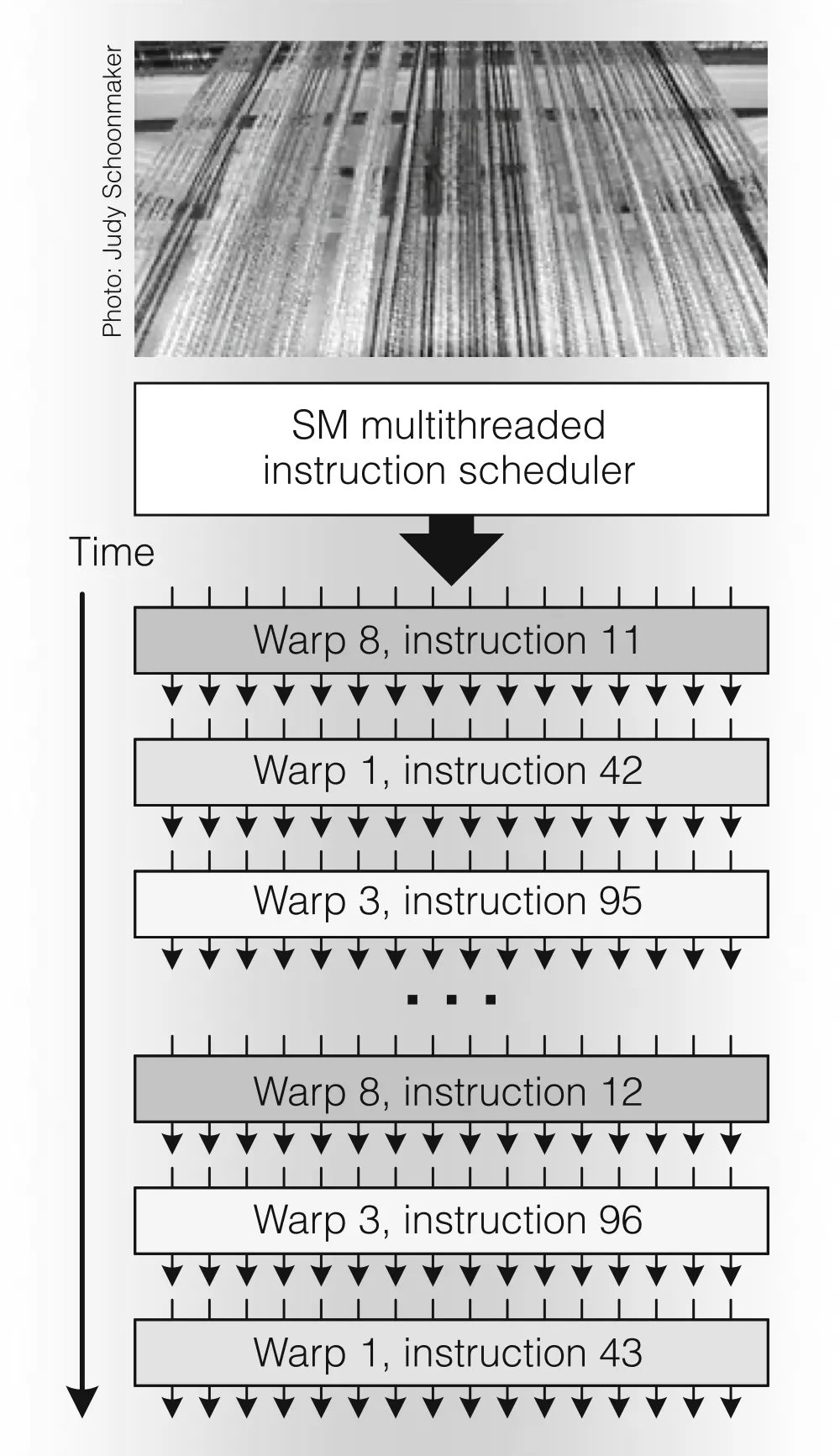
每个 SP 有 8 个,做完一个 Warp 需要 4 周期,那么 MT Issue 为什么每两个周期就分发一次指令呢?因为还有 SFU!SP 运行时,SFU 不能闲着,2 个周期分发一次指令的频率,可以保证 MT Issue 有充分的时间给 SFU 挑选一个需要运行的 Warp,这样所有员工都能满负荷运行,只要手中的 Warp 还没执行完,谁都别想停。
最后一个小问题:一个 Warp 线程的多少对性能有什么影响?如果粒度太粗,则可供调度的 Warp 就太少,不利于延迟隐藏;如果粒度太小,则每次切换所执行的线程太少,切换 Warp 的相对成本就很高。
通用计算及其“物流网”
从图形到通用计算
观察可以发现,全称为图形处理单元的 GPU,其最基本的计算部门——SM,已经和图像处理没有关系了。将图形相关操作剥离成独立的硬件,从而将计算单元 SM 解耦出来,以开启和拥抱更加广阔的并行计算市场。
在通用计算管线(原文中和通用计算管线相对应的概念是图形管线)中,所有线程都由程序员分配和调用,每个线程对应的任务不是固定的顶点或者片元,而可能是任何我们想做的事情。分配多少线程、每个线程处理什么工作(如何计算、获取什么数据、输出什么)都由程序员说了算。
另外,我们分配这些线程是协作式的,我们可以根据它们的线程 id 分配它们干不同的任务,它们之间还需要数据传递。
我们可以根据具体任务,分配线程,并设计它们的协作模式和数据依赖关系。
CUDA 和计算着色器
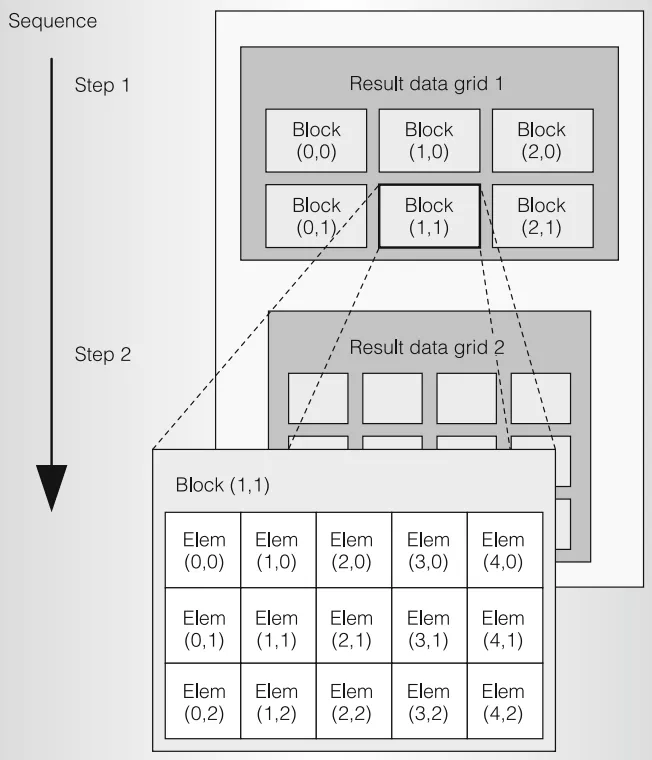
CUDA 线程的三级结构:Grid-Block-Thread,每个 Block 包含多少个线程在和函数中写死,Block 是协作发生的组织单位(也被成为 CTA,cooperative thread array),里面的线程可以通过共享内存传递数据。每个 Grid 包含多少个 Block,由应用程序在每次调用时指定,同一个 Grid 的所有 Block 之间是完全独立的,没有数据依赖。
线程相关信息的计算方法:
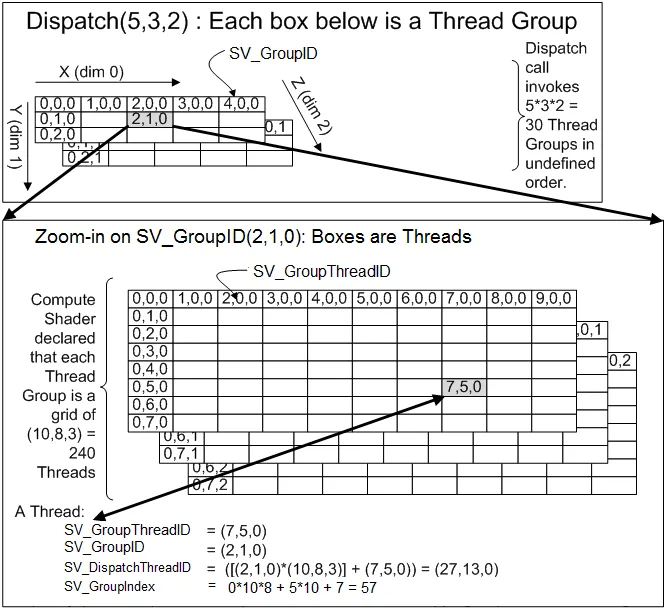
真正的并行单元是 Warp
无论上层的概念如何复杂,底层的硬件执行单元都是 SM,真正的并行单位始终是 Warp。因此优化以 Warp 为基础。
- 最好为每个 Block 分配 Warp 线程数(32)的倍数的线程数。因为不管多少线程都要拆分成Warp单位去执行,33个线程与64个线程同样需要执行两个Warp。
- 同一个分支尽量挤到同一个 Warp 中。如果可以让 Warp 1 仅执行分支 A,让 Warp 2 仅执行分支 B,则可以并行执行。否则将会串行执行。
- 如果内存读写仅有一个 Warp 执行,则不需要同步。因为一个 Warp 内部的线程本身是锁步运行的,不需要同步。但是如果不同的 Warp 之间存在数据依赖,就不得不同步。
分级“物流”系统
目前我们对于 GPU 架构的理解还差最后一块拼图:内存——支撑 GPU 这整座血汗工厂的高速运转的物流系统。
GPU 中分级物流系统,是非常自然的设计:
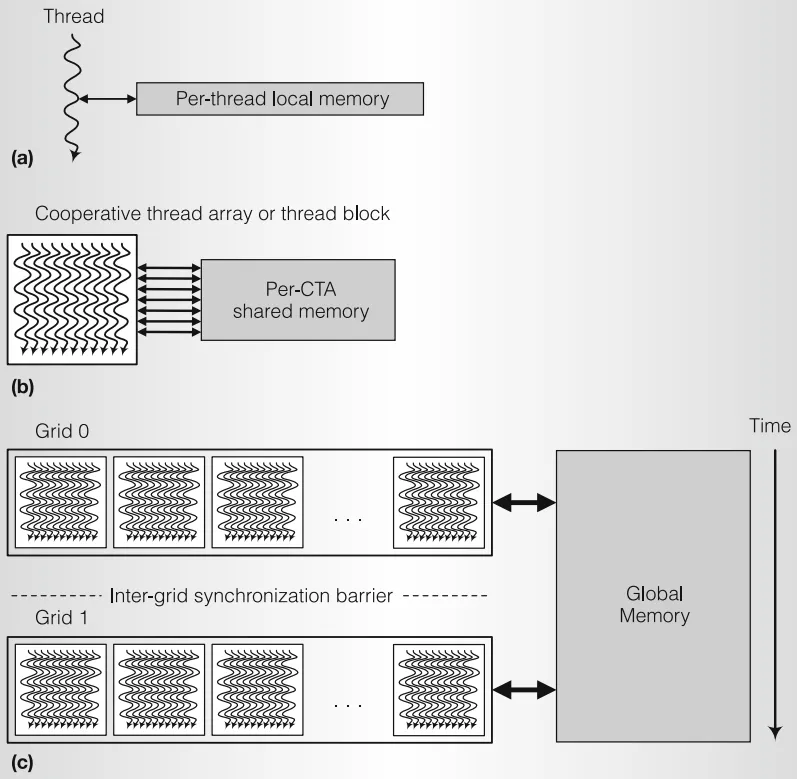
Global Memory 和 L2 Cache
Global Memory 就是 DRAM,位于 GPU 上的显存,每一块显存都与一个 L2 Cache 相连。L2 Cache 是在 SM 之外的,因此可以供所有 SM 共同使用。
不同 Grid 的执行是串行的,如果它们存在对同一块显存数据的数据依赖则由硬件负责同步。一个 Warp 中连续线程访问连续的内存,则可以被合并为一条内存读取指令。
Shared Memory 与 L1 Cache
共享内存和 L1 Cache 位于 SM 中,Tesla 架构的 L1 Cache 只用于缓存纹理数据,之后的架构中和共享内存占据相同的硬件单元,可以由用户配置两者的大小。
由于位于 SM 中,共享内存的读写速度远高于主存和 L2 Cache。
共享内存对一个 Block 中所有线程是可见的,一个 Block 中的所有线程必定位于同一个 SM 中。而同一个 Grid 的不同 Block 不一定,因此不同的 Block 之间无法通信(如果想实现通信,可以使用通信组)。这也是为啥一个 Block 中的线程数是有限的,因为一个 SM 可以容纳的 Warp 是有限的。

一个 Warp 32 线程可能需要同时对内存进行读写,需要考虑 Bank 冲突的问题。
共享内存的带宽有限,同时支持 32 个 bank 的读写,但是每个 Bank 只能读写 32 位的数据。多个地址会被映射到同一个 Bank(如上图)。如果由多个线程想读取同一个 Bank 的数据,则会变成串行执行。
Local Memory 和 Register Files
每个线程都有自己所需的局部变量,存放在寄存器中。
最初的局部变量其他线程是无法访问的,但是较新的硬件支持 Shuffle 操作,可以在一个 Warp 的线程之间直接传递数据,比共享内存更快。